High Availability Vs Fault Tolerance
Chapter 3 of Distributed Data
The ability to provide high-quality service to customers is vital for businesses to succeed. Today’s enterprise customers won’t tolerate sub-par software. They expect instant, error-free responses… with zero downtime, of course! To ensure this level of service, the infrastructure must be resilient and reliable.
Resilience has emerged as a critical factor, as even a momentary service interruption can lead customers to seek alternatives from your competitors. Understanding the underlying technology options is paramount, whether you are developing applications or implementing ready-to-use industry solutions from Macrometa.
Today’s applications are typically built using a distributed, microservice architecture, where software components can be independently deployed, updated, and versioned. These components can be distributed across multiple devices on the web, phones, desktops, and even IoT devices like traffic cameras.
In this chapter, we will attempt to highlight the two main options for making modern applications resilient. Application resilience comes in two flavors: High availability and fault tolerance. The two are often confused, so we will also attempt to describe the relevant concepts and highlight the advantages and disadvantages of each so you can choose the right resilience model for your use cases. We’ll use three case studies to illustrate the concepts and tradeoffs.
In a nutshell, fault tolerance is an upgraded version of high availability. High availability accepts that failure will occur and provides a way for the system to recover automatically, while systems with fault tolerance avoid system crashes, loss of performance, and loss of data altogether.
Executive Summary
The following table summarizes the key differences between high availability and fault tolerance.
| High Availability | Fault Tolerance | |
|---|---|---|
| Scalability | Easily scalable | Built-in |
| Load Balancing | Basic | Redundant |
| Service Disruption | Some performance degradation expected | Near zero performance degradation |
| Component Redundancy | Single point of failure only | System-wide |
| Data Loss | Rare | Not expected |
| Complexity | Medium | High |
| Cost | Medium | High |
High availability achieves resiliency by removing single points of failure in the system. In contrast, fault-tolerant systems achieve resiliency by having full copies of the system operating in parallel. They are similar in the sense that they both have near-zero downtimes, but they differ in many other respects.
Case 1: Basic License Plate Tracking System
In this example, we need to design a license plate tracking system for use on a toll road. The county wants to capture images of the license plates of passing cars on a road installed with cameras. These images will be used to figure out where to send the bill for using the toll highway. We have a minimal budget, and the county is okay if the system goes down occasionally. The basic system might look like this:
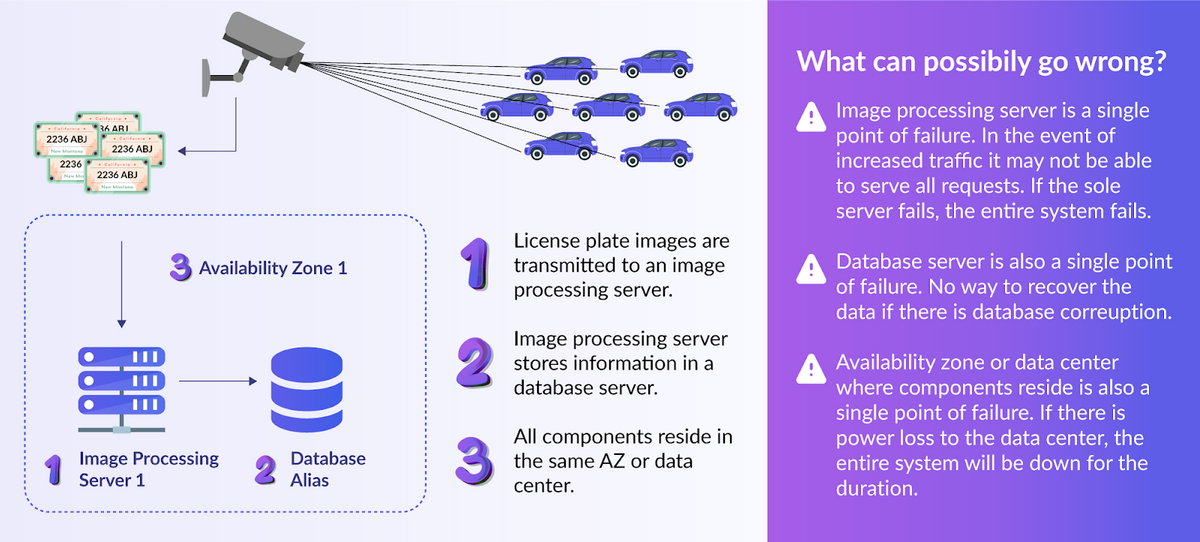
Basic License Plate Tracking System
Case 2: Highly Available License Plate Tracking System
Let’s say we were asked to build the same system for a slightly different purpose. We are told the system may also be used for surveillance, and we can’t ever have it offline.
The figure below shows one way we can design such a system to be Highly Available: we can see from the graphic that there are no single points of failure. A load-balancing service is being used with auto-scaling groups instead of an individual server. This means there are multiple image processing servers, with the possibility of more being spun up during traffic spikes. There is also more than one database server: the primary node constantly replicating to a read-only secondary node, both hidden behind a database alias. We also have more than one availability zone in use in case of a power loss that causes the data center AZ1 to go down. There may be some delays to images getting processed when only AZ2 is available because new servers can take time to spin up, and database switchover can take some time. However, despite some performance degradation, the system will stay operational.
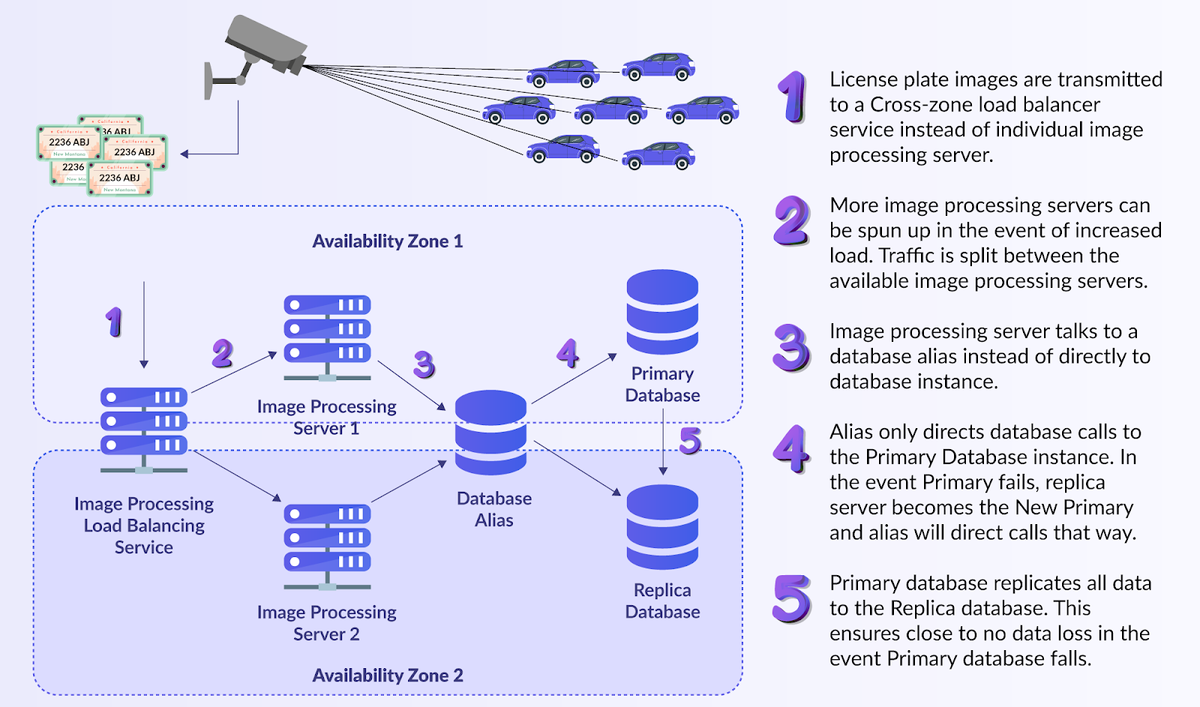
Highly Available License Plate Tracking System
The servers, databases, load balancers, and availability zones have backups, so this system can sustain component failures and stay operational. We saved some costs by not duplicating the region (the entire infrastructure exists in US East, we did not make a copy of this in US West or some other region). This system accepts some performance issues when components fail but stays available at an optimal cost. This is where high availability systems shine!
Case 3: Fault-Tolerant License Plate Tracking System
Let’s now say the requirements are even more stringent. Not only does the system need to stay operational at all times, it has to also send out time-critical alerts during critical situations (...for instance, amber alerts). Being always available is no longer enough: The system needs to be highly performant no matter the cost! The key phrase here is “no matter the cost” — this it opens the door to redundancy for all components, which is the essence of faul tolerance. The figure below shows how one might design the system for redundancy in this case.
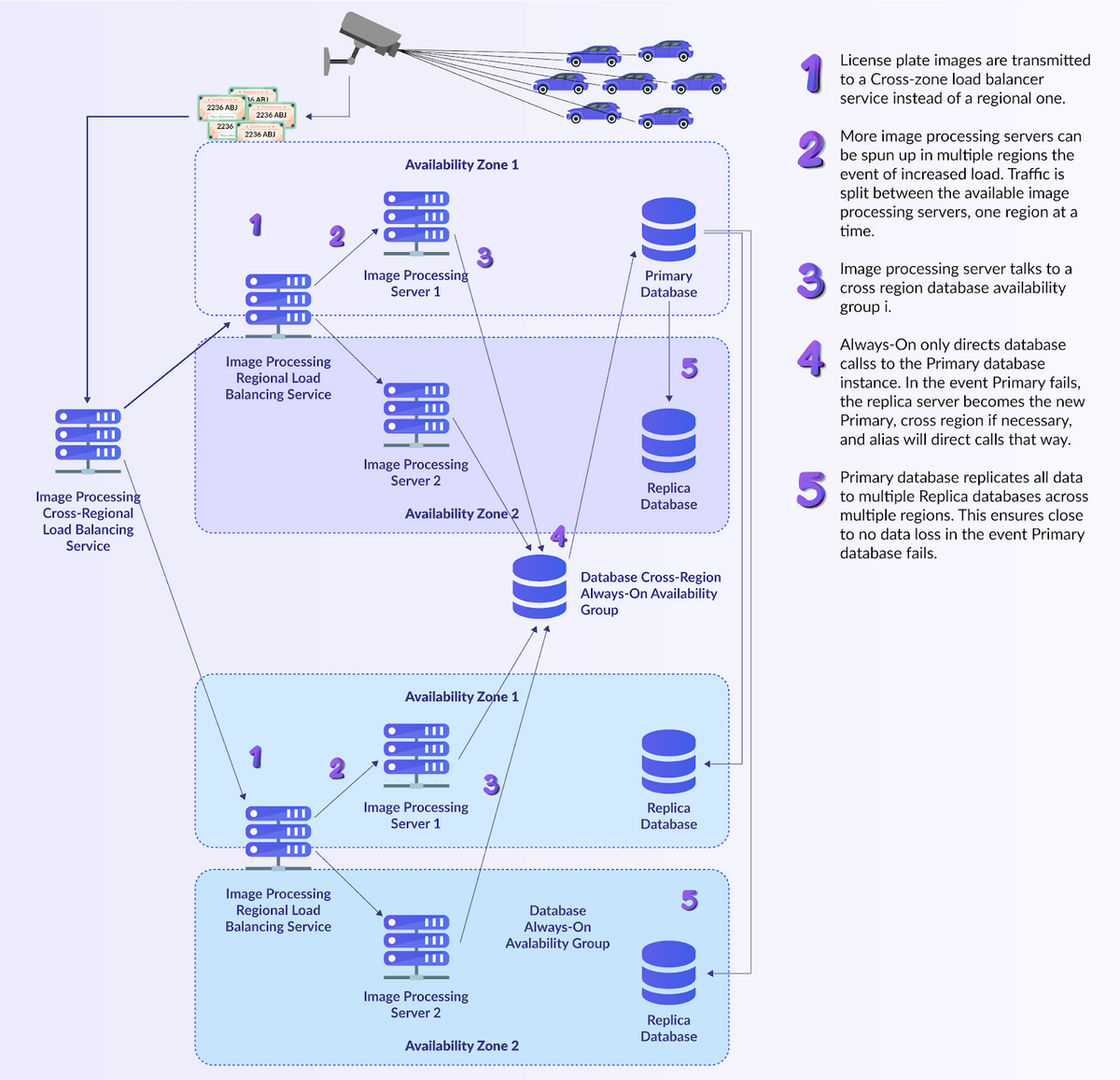
Fault Tolerant License Plate Tracking System
Similarities and Differences Between Fault-Tolerant and Highly Available Systems
Hopefully, the examples above helped illustrate how fault tolerance and high availability differ. Let’s look at these differences and similarities from various angles.
Scalability
High availability and fault-tolerant systems both leverage scalability. In the examples above, we used auto-scaling groups to ensure that traffic spikes can be handled. During times of low traffic, since high availability allows for some degraded performance, Case 2 allows for scaling down the number of image processing instances or containers to reduce cost. Case 3 is a little more constrained when scaling down because a fault tolerant system has to maintain two active regions at all times, but for that use case, we always maintained cost was never an issue!
During times of high traffic, since high availability allows for some degraded performance, Case 2 allows for scaling up the number of image processing instances or containers to handle the traffic spike. Case 3 is already built with redundancy and if needed can further scale to meet the increased demand.
Case 3 solutions can be complicated to design, especially if an application requires low-latency and happens to be globally distributed with customers spread around the globe. Fortunately, there are ready-made solutions based on leading edge technologies available in the market today for such scenarios, and enterprises don’t have to worry about having to cobble together solutions from scratch.
Load Balancing
High availability accepts some performance degradation to save on cost. When load balancing is in use for Case 2, traffic gets routed to both AZ1 and AZ2 during normal times. In the event an AZ fails, the remaining AZ will have to handle the entire load. New instances might need to be created in case of such a disaster, which may take a few seconds during which performance might be less than perfect.
Fault tolerance dictates zero performance degradation without caring how much the system costs. When load balancing is in use for Case 3, traffic gets routed to both regions during normal times, each of which has enough instances to handle the highest recorded traffic. In the event that an entire region fails, the remaining region will comfortably handle the entire load. No new instances will need to be created in case of such a disaster, so there is no performance impact. Keeping all these instances available can be costly, but if it can help resolve an amber alert, it just might be worth it!
Service Disruption
High availability systems ensure that a complete service disruption never happens. That said, they also accept that brief outages of a few seconds can happen while traffic is being diverted from an unhealthy component to a healthy one. Redirecting all traffic to AZ2 if AZ1 goes down might cause a brief service disruption.
This is not an option for fault-tolerant systems. Every system is built with complete redundancy, which ensures zero service disruption.
Complexity
Fault-tolerant systems are inherently complicated since they handle high volume while simultaneously juggling data duplication. In Case 3, we have to handle all components cross-region and ensure that every component can speak with at least one downstream component at all times without delays. High-availability systems do not make every component redundant, so fewer components need to be monitored, spun up, or connected. As a result, high availability systems are less complex.
Cost
One look at Case 3 can tell you that it involves more components than any other case. Fault-tolerant systems are inherently costlier than high availability systems. Not only are we duplicating the entire infrastructure, but there is also an added cost for monitoring, coordination, and maintenance activities that make fault-tolerant systems much more expensive than High-Availability systems.
Recommendations
When choosing between high availability and fault tolerant solutions, let your business requirements be the guide.
When dealing with a mission-critical application that can accept a small amount of data or performance losses, high availability is probably your best bet. Designing and making changes to these systems is relatively easy, and they are much easier on the pocketbook. On the downside, these systems come with hidden maintenance costs when disasters happen. You may have to deal with minor data or performance loss.
When dealing with a mission-critical application that absolutely must withstand disasters of any proportion, and where budget is less important than losing the slightest amount of data or performance, Fault tolerance is probably your best bet. Designing and making changes to these systems can get complicated and expensive, but they come through in the worst-case scenarios.
High availability is the smaller subset of fault tolerance. It focuses on removing single points of failure. It is cheaper but comes at the cost of expected minor performance degradation and data loss. Fault tolerance is more expensive, focuses on making every system component redundant, and does not tolerate any drop in performance or data loss even during disasters.
Things can get a little complicated when it comes to geo-distributed applications, especially those with low latency requirements. Latency is a real concern for such scenarios because of network transit delays that impact everything from database replication and ETL processes to user experience. Fault tolerance and High availability in such scenarios require tooling that circumvents such delays. Fortunately there are solutions like Macrometa out there that leverage new technologies like CRDTs, Edge computing, Append-only logs and Multi-Model databases to allow for fast performance while supporting fault tolerance.
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.