Hadoop Streaming
Chapter 9 of Event Stream Processing
Hadoop Streaming
Doug Cutting and Mike Cafarella officially introduced Apache Hadoop in April 2006, and it has been continuously evolving ever since. Apache Hadoop is a collection of open source software utilities that run on the network cluster using commodity hardware to solve many data and computation problems. In this article, we’ll discuss a utility from Hadoop called Hadoop Streaming and compare it to other technologies and explain how it works.
The Hadoop framework consists of a storage layer known as the Hadoop Distributed File System (HDFS) and a processing framework called the MapReduce programming model. Hadoop splits large amounts of data into chunks, distributes them within the network cluster, and processes them in its MapReduce Framework.
People often use Hadoop to refer to the ecosystem of applications built on it, including Apache Pig, Apache Hive, Apache HBase, Apache Phoenix, Apache Spark, Apache ZooKeeper, Cloudera Impala, Apache Flume, Apache Sqoop, Apache Oozie, Apache Storm, and more. There are software/utilities that don’t need Hadoop to process data, such as Kafka and Spark (which can run on both Hadoop and non-Hadoop environments), and others.
Having a thorough understanding of the technology landscape is essential, whether you are developing applications or considering ready-to-go industry solutions provided by Macrometa. By acquiring comprehensive knowledge about these technology options, you can make well-informed decisions and effectively harness the most suitable solution to cater to the unique demands of streaming and complex event processing.
Introduction to Hadoop Streaming
Hadoop Streaming is another feature/utility of the Hadoop ecosystem that enables users to execute a MapReduce job from an executable script as Mapper and Reducers. Hadoop Streaming is often confused with real-time streaming, but it’s simply a utility that runs an executable script in the MapReduce framework. The executable script may contain code to perform real-time ingestion of data.
The basic functionality of the Hadoop Streaming utility is that it executes the Mapper and Reducer without any external script, creates a MapReduce job, submits the MapReduce job to the cluster, and monitors the job until it completes.
Automated eCommerce SEO Optimization
- Prerender your website pages automatically for faster crawl time
- Customize waiting room journeys based on priorities
- Improve Core Web Vitals using a performance proxy
Hadoop vs Spark vs Kafka
There are other open source tools and utilities available in the market that perform real-time and batch analysis of big data. Choosing the best one requires extensive learning about these technologies. Hence, in this article, we have made a comparison between some popular tools that can help you to choose the best one suited for your requirements. Let us have a brief look at these tools.
Apache Spark is a fast, open source unified analytics tool suitable for big data and machine learning. Spark uses in-memory cluster computing and can handle a large volume of data by parallelizing data against its executor and cores, making it 100 times faster than conventional Hadoop analytics. Spark supports various programming languages, like Python, Java, Scala, and R, and it can run on top of Hadoop or Mesos, in the cloud or standalone.
Apache Kafka is an open source distributed event streaming tool built for real-time stream processing. Event streaming means to capture data in real time from event sources like IoT sensors, mobile devices, and databases to create a series of events. The real-time data in Kafka can be processed by the event-processing tools like Apache Spark, Kafka-SQL, and Apache NiFi.
Kafka has three main components: Producers, Topics, and Subscribers (Consumers). The Producer is the source that creates the data/event, Topics store that data/event, and the data/event is later consumed by Subscribers (Consumers). The Producers and Consumers can be programs (Java, Python, etc.), IoT devices, databases, or anything else that generates events.
Refer to the table below for other comparison criteria.
| Tools/Utility | True Streaming | Processing Framework | Performance | Scalability | Hadoop Framework | Data Retention | Languages |
|---|---|---|---|---|---|---|---|
| Hadoop Streaming | No | MapReduce | Relatively low | Scalable | Doesn’t run without Hadoop | No | Python, Perl, C++ |
| Spark Streaming | No | In-memory computation | Relatively higher | Scalable | Can work without Hadoop | No | Java, Scala, Python |
| Kafka | Yes | Java-based | High Throughput of data | Scalable | Can work without Hadoop | Configurable | Java, Python |
Hadoop Streaming architecture
In the diagram above, the Mapper reads the input data from Input Reader/Format in the form of key-value pair, maps them as per logic written on code, and then passes through the Reduce stream, which performs data aggregation and releases the data to the output.
We will discuss the operation of Hadoop Streaming in detail in the next section.
Features of Hadoop Streaming
Streaming provides several important features:
- Users can execute non-Java-programmed MapReduce jobs on Hadoop clusters. Supported languages include Python, Perl, and C++.
- Hadoop Streaming monitors the progress of jobs and provides logs of a job’s entire execution for analysis.
- Hadoop Streaming works on the MapReduce paradigm, so it supports scalability, flexibility, and security/authentication.
- Hadoop Streaming jobs are quick to develop and don't require much programming (except for executables).
Is your website ready for holiday shoppers? Find out.
Getting Started with Hadoop Streaming and its API
Shown below is the syntax to submit a MapReduce job using Hadoop Streaming and to use a Mapper and Reducer defined in Python.
> $HADOOP_HOME/bin/hadoop/streaming/hadoop-streaming-1.2.jar \
-input input_dirs \
-output output_dir \
-mapper <path/mapper.py> \
-reducer <path/reducer.py>
Where:
- input = Input location for Mapper from where it can read input
- output = Output location for the Reducer to store the output
- mapper = The executable file of the Mapper
- reducer = The executable file of the Reducer
Example:
./bin/hadoop/streaming/hadoop-streaming-1.2.jar \
-input /user/input/input.txt \
-output /user/output/ \
-mapper /home/code/mapper.py \
-reducer /home/code/reducer.py
Now let’s discuss the working steps of this Hadoop Streaming example:
- In the above scenario, we have used Python to write the Mapper (which reads the input from the file or stdin) and Reducer (which writes the output to the output location as specified).
- The Hadoop Streaming utility creates a MapReduce job, submits the job to the cluster, and monitors the job until completion.
- Depending upon the input file size, the Hadoop Streaming process launches a number of Mapper tasks (based on input split) as a separate process.
- The Mapper task then reads the input (which is in the form of key-value pairs as converted by the input reader format), applies the logic from the code (which is basically to map the input), and passes the result to Reducers.
- Once all the mapper tasks are successful, the MapReduce job launches the Reducer task (one, by default, unless otherwise specified) as a separate process.
In the Reducer phase, data aggregation occurs and the Reducer emits the output in the form of key-value pairs.
Popular Hadoop Streaming parameters
| Parameters | Required or Optional? | Description |
|---|---|---|
| -input | Required | Input directory or file location for the Mapper. |
| -output | Required | Output directory location for the Reducer. |
| -mapper | Required | Mapper file (for Python) or Java class name or executable. |
| -reducer | Required | Reducer file (for Python) or Java Class name or executable. |
| -inputformat | Optional | The Java class name should return the key-value pair from the input specified other than the text format. Default is TextInputFormat. |
| -outputformat | Optional | The Java class name should return the key-value pair from the output specified other than the text format. Default is TextOutputFormat. |
| -partitioner | Optional | The Java class name behaves as a partitioner that partitions the data based on the key. |
| -combiner | Optional | The Java class combines the output from the Mapper into one stream before sending the data to the Reducer. |
| -cmdenv name=value | Optional | Passes the environment variable to streaming commands. |
| -verbose | Optional | Used to get verbose output. |
| -numReduceTasks | Optional | Specifies the number of reducers to act. Default is 1. |
| -mapdebug | Optional | An additional script path will be called when the Map task fails. |
| -reducedebug | Optional | An additional script path will be called when the Reduce task fails. |
Hadoop Streaming use case
A popular example is the WordCount program developed in Python and run on Hadoop Streaming. Let's look at this example step by step.
- Create a new file and name it mapper.py. Paste the code below into the file and save it.
!/usr/bin/python
import sys
# Input reads the text file from the stdin
for line in sys.stdin:
# Strips the trailing and leading whitespaces and breaks the line into words
words = line.strip().split()
# Iterate the words list
for word in words:
# Write the results to standard output in the form of key-value pairs separated by tabs
print('%s\t%s' % (word, 1))
- Create another new file named reducer.py, containing the code below.
# !/usr/bin/python
import sys
# Initializing some variables
current_word = ""
current_count = 0
word = ""
# Input reads from stdin (mapper outputs to stdout)
for line in sys.stdin:
# Strip and split the words from the Mapper to get word and count
word, count = line.strip().split('\t', 1)
# convert count string to int
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print('%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print('%s\t%s' % (current_word, current_count))
- Create an input file with some lines in it, such as some contents from Wikipedia, and paste them into the file. Save the file in the Hadoop location /user/input/input.txt
The file may look like this -

- Submit the Mapreduce job with following command:
$./bin/hadoop/streaming/hadoop-streaming-1.2.jar \
-input /user/input/input.txt \
-output /user/output/ \
-mapper /home/code/mapper.py \
-reducer /home/code/reducer.py

- Once the job is successful, you will see some part files in /user/output location.
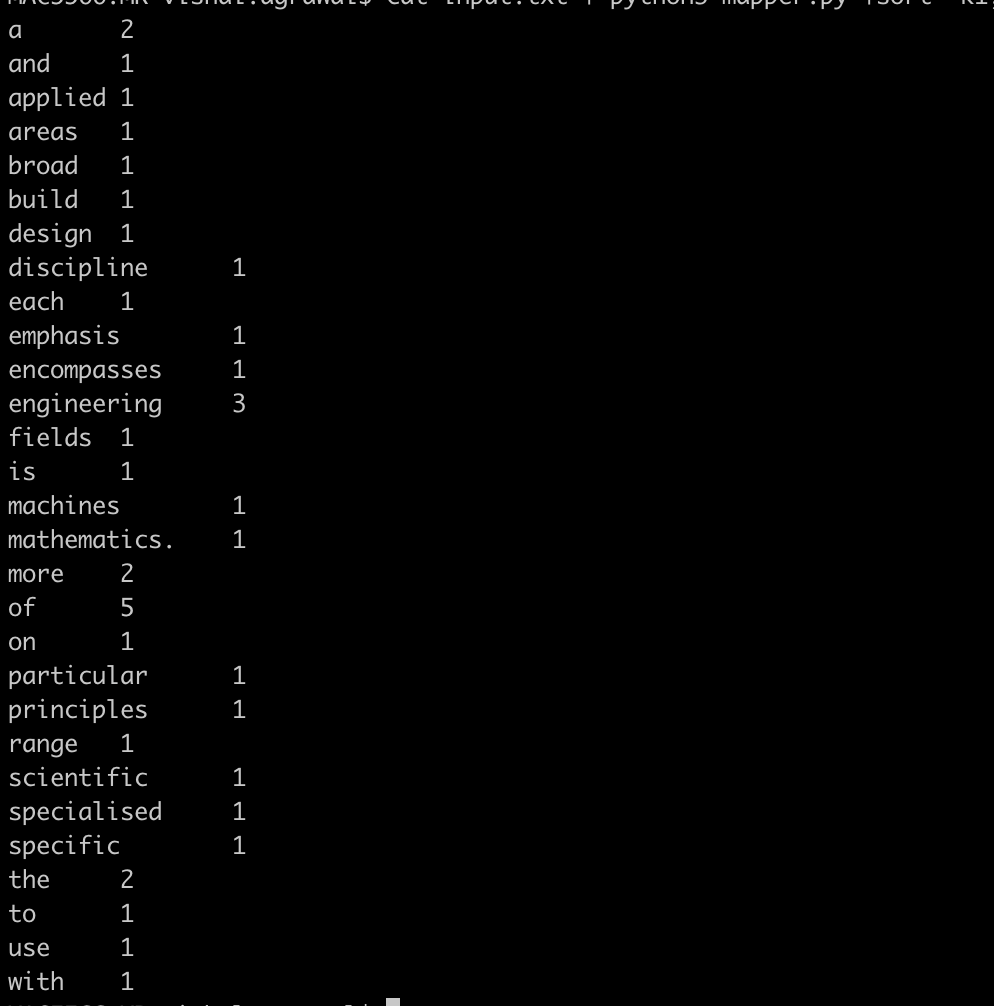
- To view the content of the file, open it in any editor. It will look something like this. (Content may vary depending upon the content in the input file)
Compare
| Platform | Batch | Complex Events | Streams | Geo-Replication | Database | Graphs |
|---|---|---|---|---|---|---|
| Spark | ✔️ | ✔️ | ✔️ | |||
| Flink | ✔️ | ✔️ | ✔️ | ✔️ | ||
| Macrometa | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
Conclusion
This article reviewed Hadoop Streaming, its features, architecture, and its use case. Hadoop Streaming executes non-Java code in the MapReduce paradigm, but new open source projects like Spark and Kafka are gradually replacing Hadoop. One of the reasons for this is that Spark is faster than Hadoop due to its in-memory computation. Spark also supports multiple languages, accommodating a broader spectrum of development projects.Kafka is known for its scalability, resilience, and performance. Together, Spark and Kafka process data in real-time and offer real-time analytics – something that Hadoop does not offer.
Macrometa is a hyper distributed cloud modern designed to help businesses overcome the limitations of centralized cloud platforms. Macrometa offers noSQL database, pub/sub, and event processing services into a single Global Data Network (GDN) that lets you develop a pipeline with minimal code. Request a trial to try it out or chat with one of our solution experts. Explore our ready-to-go industry solutions that address the most complex problems.
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.