The Guide To DynamoDB Streams
Chapter 2 of Event Stream Processing
The guide to DynamoDB streams
When you think of a database and how its information is used, you might picture a centralized repository that collects raw data from several sources. Once collected, that information is then processed to accomplish certain goals (such as complete a search) or reveal some insights (like complete an analysis). While this is a traditional model for databases, it is not the only way to interact with the data that you collect.
Before we dive into this article, we wanted to introduce Macrometa’s edge computing platform with all the features of AWS DynamoDB and a stream processing engine. Learn more about the technology or explore Macrometa's AI-powered PhotonIQ solutions that can address your most complex problems. Now back to the article!
In this article, we’ll explore an alternative to the standard database model known as stream processing. Stream processing works by processing data mid-stream, while it’s in motion, or even directly from its data source in real-time. Stream processing can support several business intelligence use cases with near real-time experience for end-users.
What is DynamoDB?
DynamoDB is a fully-managed NoSQL database service that provides seamless scaling. It supports unlimited concurrent read and write operations and touts single-digit millisecond latency. Since it is a serverless and cloud-based managed service, users don’t have to manage infrastructure details (such as the number of servers). DynamoDB is straightforward to get running; its tables are schema-on-reading instead of schema-on-write, and they can be created with just a few clicks or commands.
Automated eCommerce SEO Optimization
- Prerender your website pages automatically for faster crawl time
- Customize waiting room journeys based on priorities
- Improve Core Web Vitals using a performance proxy
What are DynamoDB streams?
A DynamoDB Stream is a time-ordered sequence of events recording all the modifications for DynamoDB tables in near real-time. Similar to change data capture, DynamoDB Streams consist of multiple Insert, Update, and Delete events. Each record has a unique sequence number which is used for ordering. Stream records are grouped in shards, each shard containing the information to access and iterate through those records. Shards are automatically created and scaled transparently from the users.
DynamoDB streams are a bit like a direct messaging queue integration (Kinesis/Kafka) with a table that contains all the events that are happening in the table. This differs from usual streaming where data can be a complete business object. In a DynamoDB stream, users are limited to the table that triggered the stream events.
DynamoDB streams are stored for 24 hours with no flexibility to extend (like for Kinesis Streams), even if there is available disk space (like for Kafka). DynamoDB Streams automatically scale shards using the built-in partition auto-scaling functionality.
Getting started with DynamoDB streams
StreamSpecification is used for the configuration of the DynamoDB Streams on a table. We also need to specify what type of information and which keys need to be added into the stream event.
- StreamEnabled: Determines if the stream is on or off for a given table.
- StreamViewType: Determines which information needs to be added into the stream event whenever there is a data change in a table.
- KEYS_ONLY: Determines which item keys (primary key, sort key) are available during the stream event.
- NEW_IMAGE: Determines whether the entire item is shared after all the changes have been applied.
- OLD_IMAGE: Determines whether the entire item is available before any changes have been applied.
- NEW_AND_OLD_IMAGES: Determines whether the item is available both before and after changes have been applied.
When Streams on the DynamoDB table are enabled/disabled, a new stream with a unique descriptor is created. This unique descriptor will need to be used whenever we change the settings.
There are different ways to consume a DynamoDB stream, but the most common approach is to use the Lambda functions. Lambda triggers whenever it detects an update based on different DynamoDB stream events and is made accessible through function parameters.
DynamoDB stream use cases
Let’s examine a typical DynamoDB example. In this scenario, we are working on a simple task management application where users can create lists with multiple actionable tasks. The front-end is a web application, android, and iOS mobile application with the backend leveraging DynamoDB.
One DynamoDB table called todoListTask stores the different tasks for a list. Each list can contain multiple tasks with the creation date. ListId is the partition key while TaskId is unique and is used as the sort key. With this in mind, the table’s schema is as follows:
| Partition Key | Sort Key | Attribute 1 | Attribute 2 |
|---|---|---|---|
| ListId | TaskId | Description | Created_date |
| 1 | 1_start | start | 20052021 |
| 1 | 2_progress | Continue working | 20052021 |
| 2 | 1_start | Start the hustle | 20052021 |
When a new item is inserted into the list, it triggers the respective event and generates the entry for the stream. If we insert the following item:
| Partition Key | Sort Key | Attribute 1 | Attribute 2 |
|---|---|---|---|
| 2 | 1_progress | Share progress | 20052021 |
It should then generate the following entry for the DynamoDB stream:
| View Type | Values |
|---|---|
| New Image | TaskId=1_progress, ListId=2, Description=Share progress, Created_date=20052021 |
| Keys only | TaskId=1_progress, ListId=2 |
Let’s examine different use cases and scenarios for that same application using DynamoDB Streams.
- Providing fast access across regions with cross-region replication
1. Providing fast access across regions with cross-region replication
If your users are based across the globe (e.g. US and Europe) and your database is hosted in one of the US regions, it will add latency for the users in Europe. The most common solution for this challenge would be to create table replicas in some of the regions closer to your European customers. Although this improves the read response time for the users, it also introduces synchronization challenges between replicas. Replicas need to be synchronized with either eventual consistency or latency, but not both.
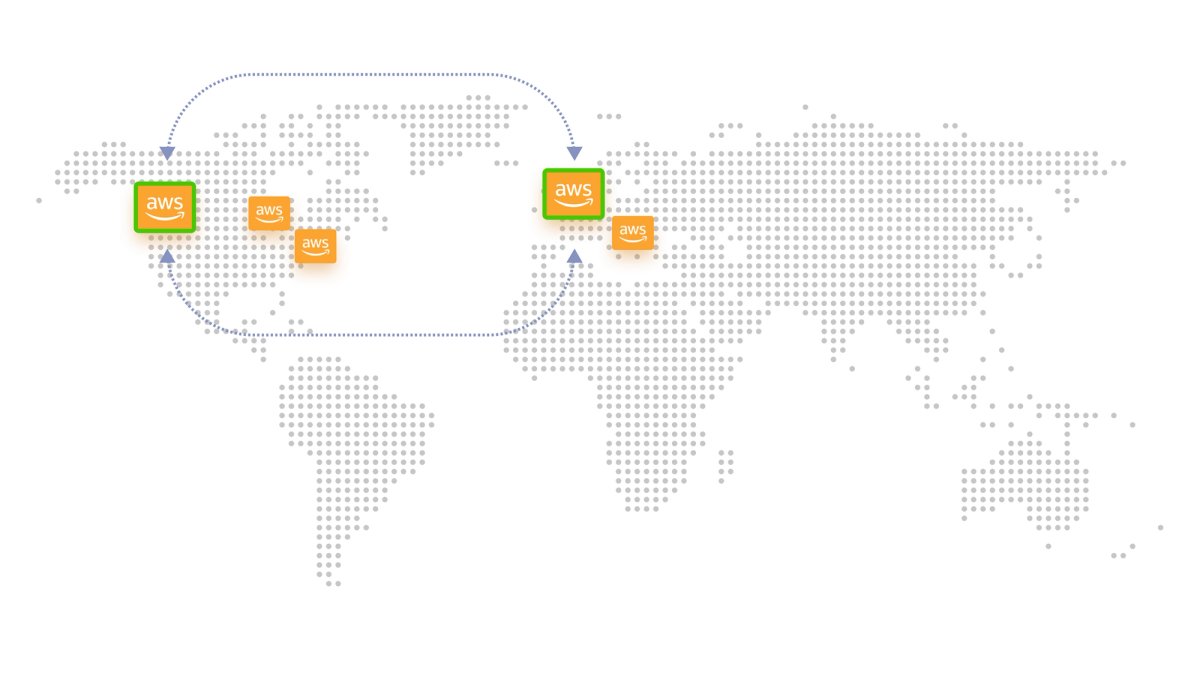
Illustration of Syncing Regional Database Replicas
DynamoDB Streams with Lambda can be used to replicate data from the master table to other replicas. However, this custom solution is a challenging to maintain and can be error-prone. An alternative is to use DynamoDB’s global tables. Global tables are a ready-made, multi-master, and cross-region replication solution provided by DynamoDB for applications with users in different parts of the world. Essentially, it performs table synchronization in the background. You can find global table availability for different regions.
Strong, consistent operations need to be happening on the same region replica because Global tables only support consistent reads for cross-region operations. If you read from a different replica than the one you write to, it may receive the stale data. In case of conflict for different replicas, it will use the last writer win policy.
Global tables are configured while creating a table or later if the replica table is still empty. There are a few details that need to be addressed while configuring the global tables:
- Only one replica per region is allowed.
- The table must have Streams enabled with new_and_old_images specifications.
- Table name and keys across regions should be the same.
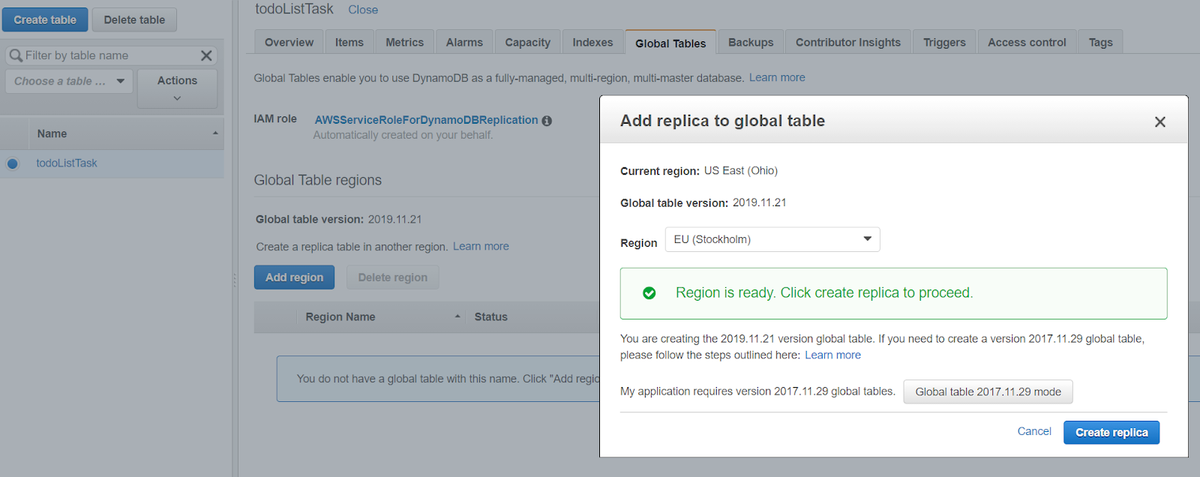
Screenshot of Adding a Replica to a Global Table
2. Aggregating the data into another table
Let’s say we have a lot of data and, for caching reasons, want to maintain the count of tasks for each list in the todoTaskCount table. This table needs to be updated when a new task is added to the list so that the application user can see the updated task count. The table schema is as follows:
| Partition Key | Attribute 1 |
|---|---|
| ListId | TaskCount |
| 1 | 2 |
| 1 | 2 |
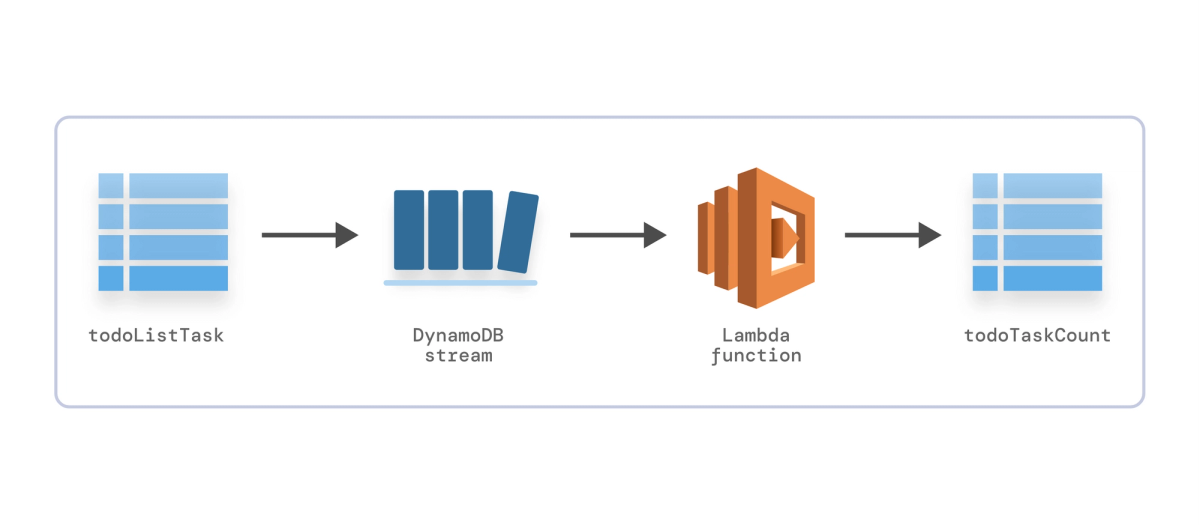
Using DynamoDB Streams and Lambda
We start by creating our new table, todoTaskCount. Then, we enable DynamoDB Streams on our todoListTask table with new images only (since we don’t need to see the old values). Finally, we create the Lambda function with the proper IAM roles used for execution.
3. Indexing tasks for search optimizations
Our application is being used by a large number of customers and they have requested a new feature that allows them to perform task searches. To do that, we must index the task as soon as it is created by the user. Since DynamoDB is not the ideal solution for search functionality, our team decides that a fully-managed service like Amazon ElasticSearch is the best option.
To implement Amazon ElasticSearch, we can add a step when creating the task to index the task into the cache as well. This solution works, but it adds additional latency for each request.
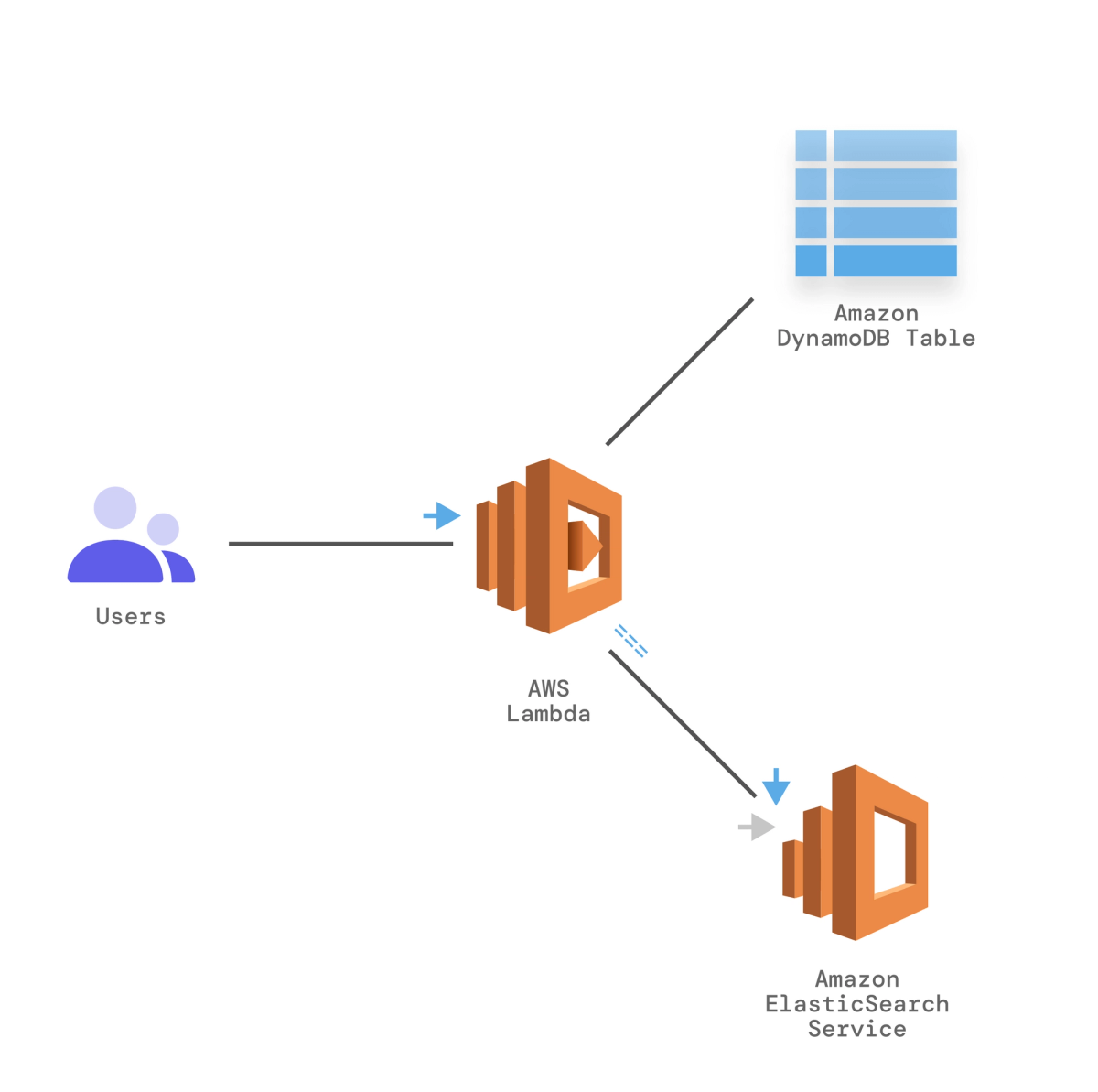
Splitting the Indexing Process From Task Creation
With DynamoDB Streams, indexing to ElasticSearch can be split from the task creation process to ensure that the request-response time for end-users is not affected. Once a task is created, a stream is generated for the downstream Lambda function to look for newly-added tasks instead of scanning the whole table to query the changes.The Lambda function then calls the ElasticSearch service to index the recently-added values. This allows our front-end application to pull data from the database efficiently.
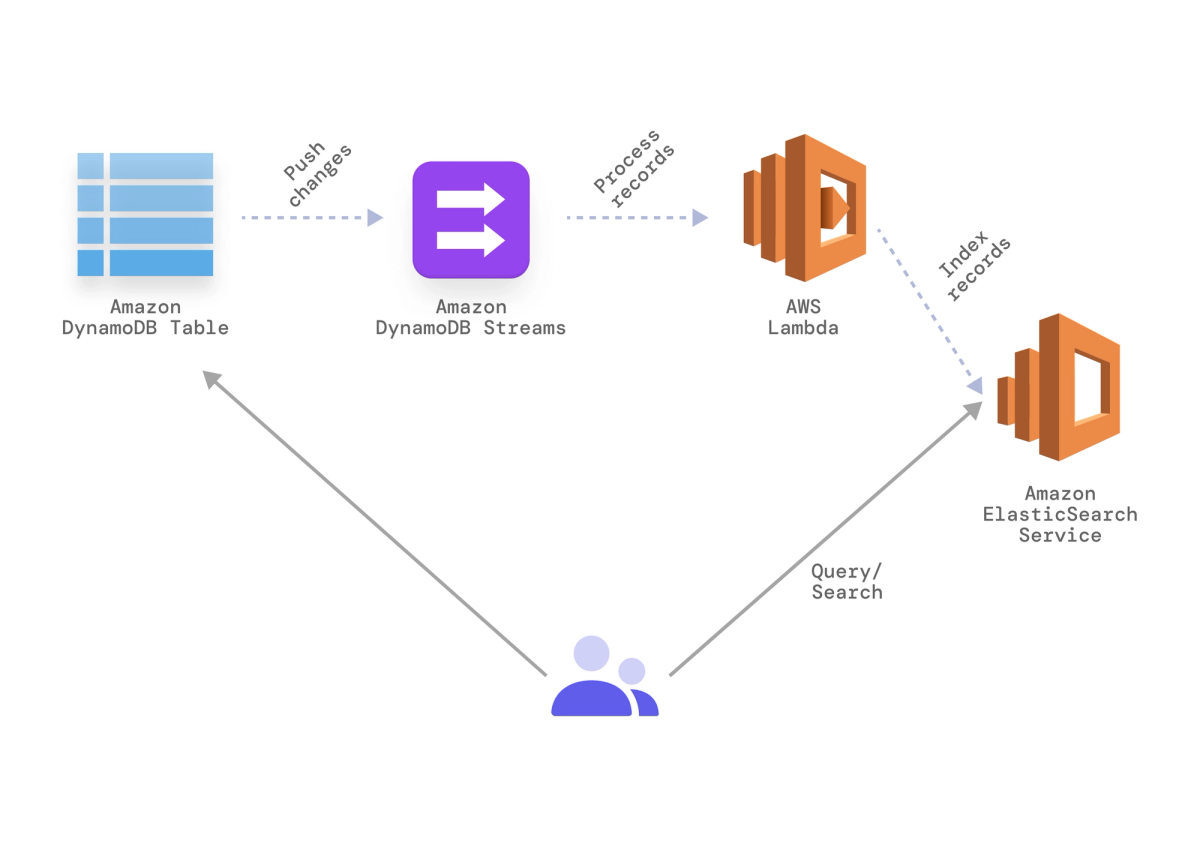
Using AWS ElasticSearch with DynamoDB
Finally, we’ll create an ElasticSearch cluster for indexing the items. Once we have the service up and running, we need to set up our Lambda function as shown. Luckily, we can use one of the existing templates to point it to our own ElasticSearch service.
4. Auto-archiving using TTL and Lambda
Our task management application grows to support enterprise-level clients. These clients have requested archive functionality to better manage their growing list of tasks and task lists.
A quick solution would be using soft deletion, but that can increase the table size with unnecessary data. Instead, the team decides to maintain a separate table called todoListTaskArchived for archived items. This is achieved with the DynamoDB TTL (Time to Live) feature on the table and then connecting the Lambda function with the DynamoDB Streams to perform actions.
TTL is a feature of DynamoDB that expires an item from the table based on a specific timestamp attribute. Once an item has expired (TTL value is less than the current EPOCH time), it is removed. However, this removal process can take up to 48 hours before the items are actually deleted from the table. While developing applications with TTL, developers will need to set up a mechanism to filter out these items during normal operations.
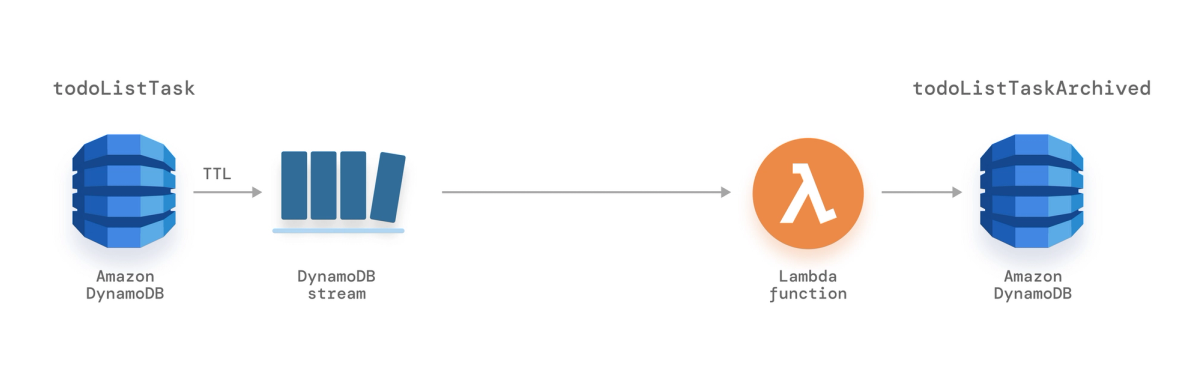
Archiving Tasks Via TTL Attribute
This can be achieved by adding an expires attribute to the table that populates the current timestamp for archived tasks. This attribute also triggers the remove event for the streams captured by the Lambda function.
We’ll enable the TTL on the table todoListTaskArchived and use an expires column for time to live attribute settings. Since the lambda function captures the changes after the items in the table expire, we will configure the streams with New and Old images as well.
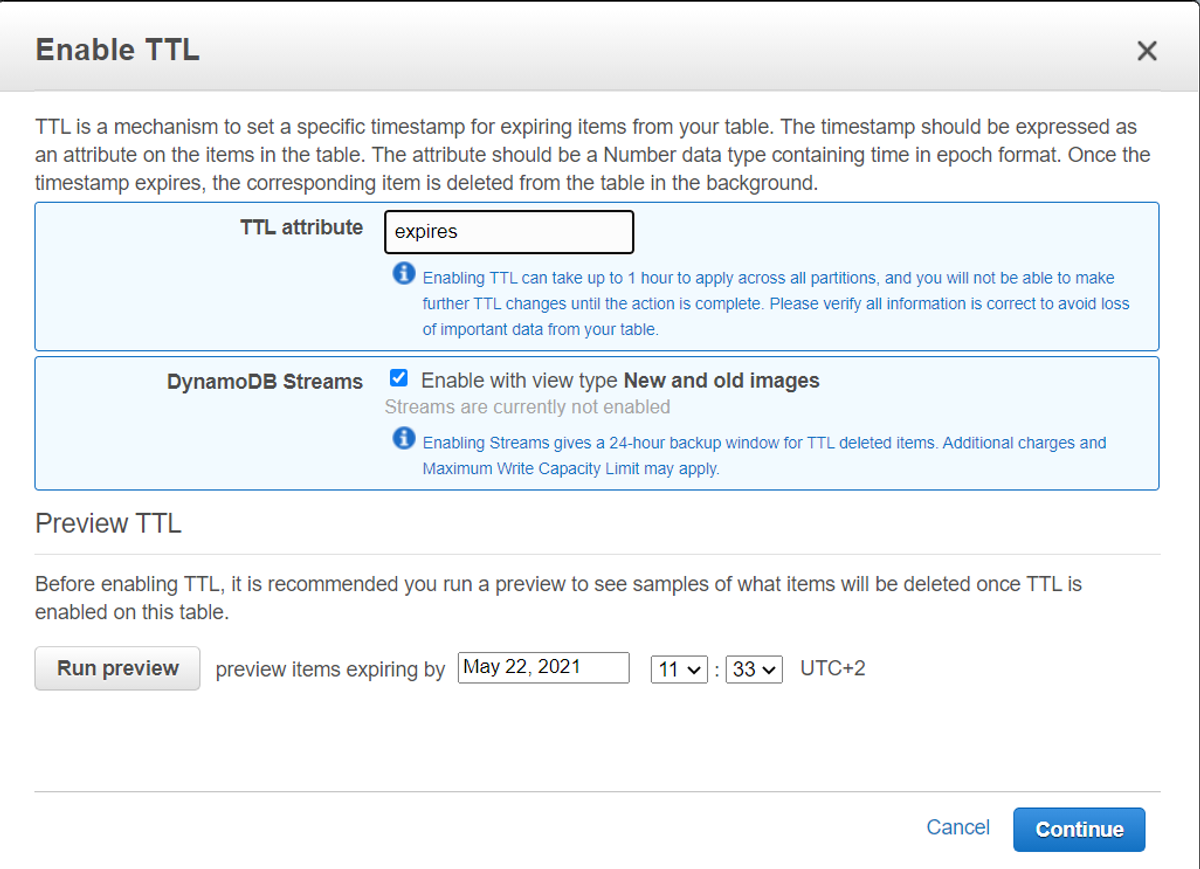
Screenshot of Enabling a TTL (Time to Live) Attribute
This code snippet sets up the lambda function to move the items into the archive table.
const AWS = require("aws-sdk");
const dynamodb = new AWS.DynamoDB();
exports.handler = (event, context, callback) => {
event.Records.forEach((record) => {
if(record.eventName == 'REMOVE') {
let params = {
TableName: "todoListTaskArchived",
Item: record.dynamodb.OldImage
};
dynamodb.putItem(params, (err, data)=>{
if(err) {
console.log(err);
} else {
console.log(data);
}
});
}
});
callback(null, `Successfully processed ${event.Records.length} records.`);
};
Is your website ready for holiday shoppers? Find out.
DynamoDB best practices
- Standardize the settings and indexes used in Global tables across regions (e.g., TTL, local, or global secondary index; provisioned throughput).
- Filter for expired items by including an
expirestable attribute since TTL does not happen in real-time.
Conclusion
Stream processing is a real-time model for interacting with information passed to your databases and is extremely powerful for business intelligence functions. There are many ways to orchestrate stream processing, and DynamoDB is one of the more-widely used.
DynamoDB Streams can be combined with other AWS services like ElasticSearch and Lambda. This setup offers real-time responses and search functionality, while also filtering for expired (TTL) items.
If you would like to consider a less expensive way to accomplish your objectives, learn how you can get the DynamoDB experience on any cloud and at the edge with 50X better latency with customized solutions built on the Macrometa GDN.
Learn more about Macrometa
It is crucial to have a deep comprehension of the technology landscape, whether you are customizing applications on the Macrometa Global Network or assessing PhotonIQ solutions. PhotonIQ offers powerful features like Event Hub, which can deliver millions of notifications per second, and FaaS, enabling you to deploy serverless apps in less than a minute, faster than AWS Lambda. View our PhotonIQ demos, or chat with an expert if you have any questions.
Compare
| Platform | Batch | Complex Events | Streams | Geo-Replication | Database | Graphs |
|---|---|---|---|---|---|---|
| Spark | ✔️ | ✔️ | ✔️ | |||
| Flink | ✔️ | ✔️ | ✔️ | ✔️ | ||
| Macrometa | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
Like the Article?
Subscribe to our LinkedIn Newsletter to receive more educational content.