Part 4 - Import Traits and Merge
This section explains how to use queries to combine information in collections.
References to Other Document Collections
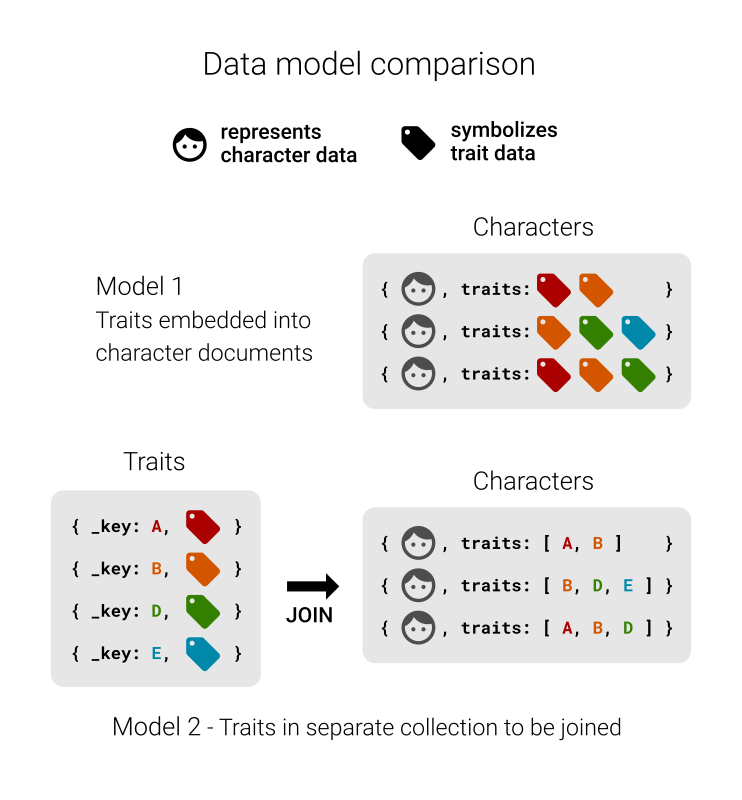
The character data you imported has an attribute traits for each character, which is an array of strings. It does not store character features directly, however. Instead, it lists letters that represent traits. For example, Ned Stark has five traits.
{
"name": "Ned",
...
"traits": ["A","H","C","N","P"]
}
The idea here is that traits is supposed to store documents keys of another collection, which you can use to resolve the letters to labels such as strong. By using another collection for the actual traits, you can easily query for all existing traits later on and store labels in multiple languages for instance in a central place. If you embedded traits directly, it becomes unmanageable.
Here's Ned Stark with his traits written out:
{
"name": "Ned",
...
"traits": [
{
"de": "stark",
"en": "strong"
},
{
"de": "einflussreich",
"en": "powerful"
},
{
"de": "loyal",
"en": "loyal"
},
{
"de": "rational",
"en": "rational"
},
{
"de": "mutig",
"en": "brave"
}
]
}
If you were to rename or translate one trait, then you would need to find all other character documents with the same trait and perform the changes there too. If you only refer to a trait in another collection, then you just need to update one record in a single document.
Import Traits Data
Below you find the traits data. Follow the pattern shown in Create Documents to import it:
- Create a document collection named Traits.
- Assign the data to a variable in C8QL,
LET data = [ ... ]. - Use a
FORloop to iterate over each array element of the data. INSERTthe elementINTO Traits.
[
{ "_key": "A", "en": "strong", "de": "stark" },
{ "_key": "B", "en": "polite", "de": "freundlich" },
{ "_key": "C", "en": "loyal", "de": "loyal" },
{ "_key": "D", "en": "beautiful", "de": "schön" },
{ "_key": "E", "en": "sneaky", "de": "hinterlistig" },
{ "_key": "F", "en": "experienced", "de": "erfahren" },
{ "_key": "G", "en": "corrupt", "de": "korrupt" },
{ "_key": "H", "en": "powerful", "de": "einflussreich" },
{ "_key": "I", "en": "naive", "de": "naiv" },
{ "_key": "J", "en": "unmarried", "de": "unverheiratet" },
{ "_key": "K", "en": "skillful", "de": "geschickt" },
{ "_key": "L", "en": "young", "de": "jung" },
{ "_key": "M", "en": "smart", "de": "klug" },
{ "_key": "N", "en": "rational", "de": "rational" },
{ "_key": "O", "en": "ruthless", "de": "skrupellos" },
{ "_key": "P", "en": "brave", "de": "mutig" },
{ "_key": "Q", "en": "mighty", "de": "mächtig" },
{ "_key": "R", "en": "weak", "de": "schwach" }
]
Resolve Traits
Let's start simple by returning only the traits attribute of each character:
FOR c IN Characters
RETURN c.traits
[
{ "traits": ["A","H","C","N","P"] },
{ "traits": ["D","H","C"] },
...
]
You can use the traits array together with the DOCUMENT() function to use the elements as document keys and look up them up in the Traits collection:
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)
The results return a Trait document with all fields for each trait for each character. Here is part of the first one:
[
[
{
"_key": "A",
"_id": "Traits/A",
"_rev": "_V5oRUS2---",
"en": "strong",
"de": "stark"
},
{
"_key": "H",
"_id": "Traits/H",
"_rev": "_V5oRUS6--E",
"en": "powerful",
"de": "einflussreich"
},
{
"_key": "C",
"_id": "Traits/C",
"_rev": "_V5oRUS6--_",
"en": "loyal",
"de": "loyal"
},
{
"_key": "N",
"_id": "Traits/N",
"_rev": "_V5oRUT---D",
"en": "rational",
"de": "rational"
},
{
"_key": "P",
"_id": "Traits/P",
"_rev": "_V5oRUTC---",
"en": "brave",
"de": "mutig"
}
],
[
{
"_key": "D",
"_id": "Traits/D",
"_rev": "_V5oRUS6--A",
"en": "beautiful",
"de": "schön"
},
],
...
]
This is a bit too much information, so let's only return English labels using the array expansion notation:
FOR c IN Characters
RETURN DOCUMENT("Traits", c.traits)[*].en
The results list just the English labels for each character:
[
[
"strong",
"powerful",
"loyal",
"rational",
"brave"
],
[
"beautiful",
"powerful",
"loyal"
],
...
]
Merge Characters and Traits
Great, you resolved the letters to meaningful traits! But which character do they belong to? With the MERGE() operation, you can combine the character document and the data from trait document:
FOR c IN Characters
RETURN MERGE(c, { traits: DOCUMENT("Traits", c.traits)[*].en } )
Results will be similar to the following:
[
{
"_id": "Characters/2861650",
"_key": "2861650",
"_rev": "_V1bzsXa---",
"age": 41,
"alive": false,
"name": "Ned",
"surname": "Stark",
"traits": [
"strong",
"powerful",
"loyal",
"rational",
"brave"
]
},
{
"_id": "Characters/2861653",
"_key": "2861653",
"_rev": "_V1bzsXa--B",
"age": 40,
"alive": false,
"name": "Catelyn",
"surname": "Stark",
"traits": [
"beautiful",
"powerful",
"loyal"
]
},
...
]
Because you used an object { traits: ... } which has the same attribute name traits as the original character attribute, the latter is overwritten by the merge.
For more information, refer to MERGE().
Next Steps
Great job! You can now combine data from different collections. When you're ready, continue the tutorial in Part 5 - Graph Traversal.